
The first International Challenge on Mobile Masked Face REcognition Database (M2FRED), held in conjunction with the 21th International Conference on Image Analysis and Processing (ICIAP2021)
About M2FRED Challenge
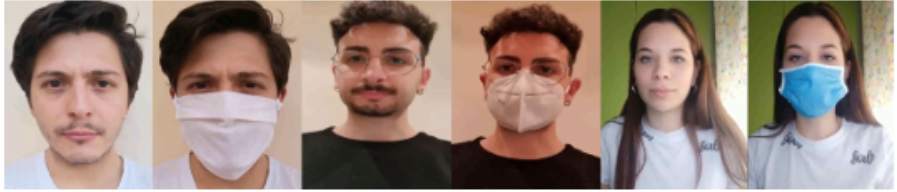
Recent regulations to block the widespread transmission of COVID disease among people impose the use of facial masks indoor and outdoor. Such restriction becomes critical in all those scenarios where access controls take benefit from biometric face recognition systems. The occlusions due to the presence of a facial mask make a significant portion of human faces unavailable for feature extraction and analysis. The M2FRED challenge aims at exploring the contribution of the solely periocular region of the face to achieve a robust recognition approach suitable for mobile devices. Rather than working on a static analysis of the facial features, like largely done by work on periocular recognition in the literature, the M2FRED dataset proposes the challenge of analysing face dynamics so that the spatio-temporal features make the recogniser frame-independent and tolerant to user movements during the acquisition. To obtain a lightweight processing, which is compliant with limited computing power of mobile devices, the spatio-temporal representation of the periocular region must be done with a lightweight processing, potentially involving simpler machine learning classifiers over the well-known deep learning classifiers (which have been proved extremely promising but also significantly demanding). Moreover, the cross-device nature of the M2FRED dataset makes the detection of the facial features and their analysis even more complex due to the different acquisition conditions among all participants in the dataset. The challenge is configured as an open-set biometric recognition, meaning that the testing stage of the challenge will involve the presence of known subjects in the training set and the submitted algorithm must intercept such a case.
The protocol:
In order to join the M2FRED competition, each participant is asked to submit a registration form first. Once correctly registered, the participant can also submit more than one executable application.
Registration
- Each participant must fill and submit a registration form.
- Each submission is associated with a username chosen by the participants. The username will be also used as a name for the submitted executable.
- Each participant is allowed to submit more than a single executable or multiple separated variants of the same algorithm. In case of multiple submissions, only one registration form is required.
Executable
- Each executable testing algorithm should be able to receive from the command line the path of the test video directory and should produce a .txt file with the predicted label corresponding to each video of the test set (NOTE: the unknown subject should be associated/marked with the label -1). The resulting file should also contain the overall accuracy and precision scores.
- The order of inputs is strictly defined and simple. Let D1 = path to the directory with the test videos . Let APP be the executable application, then by running:
APP D1
a TXT file containing the predicted_label is then created. Such a TXT file must have the following properties:- the name of the video with the corresponding predicted label and the overall accuracy and precision score in the last two lines.
- it is saved in path (preferably something like “./results”);
- its filename is results.txt;
- its content, in each line, is the videoName [whitespace] predicted label. As the last two lines the overall accuracy and precision score, respectively;
- The accuracy score accuracy=tp+tntp+tn+fp+fn is meant as the ratio between the correctly predicted positive values (True Positive, TP) and the correctly predicted negative values (True Negatives,TN) for the total classifications made, including False Positives FP and False Negatives FN.
- The precision scoreprecision=tptp+fp is meant as the ratio between the correctly predicted positive values (True Positive, TP) for the total predicted positive values, both ture (True Positive, TP) and false (False Positives FP).
- The participants can use the whole M2FRED dataset for developing and performing experimentations of their proposed algorithm. The participants should take into account that the dataset is going to be extended with new acquisitions by new mobiles and of new subjects according to the same acquisition protocol applied to the current version of the database. The testing stage of the challenge will be run on a subset of the new version of M2FRED that will be revealed together with the final ranking.
- Participants must consider that the best algorithm submitted to the M2FRED Challenge will be used to test the correctly predicted positive values (True Positive, TP) (model precision and accuracy). Since it will be used also for the final ranking of submitted algorithms, participants are invited to use it for testing their proposal.
- Each executable is supposed to be self-contained and it will not have access to the Internet. No additional download has to be expected to run the application. The submitted proposal must therefore contain all supporting files (dlls, libraries and so on) useful to its proper running. In case of open-source code submitted to the challenge, the authors are invited to use Python as a preferred programming language and specify all the requirements. Github version of the code or any other similar approach is also welcome.
- The executable can be written in any programming language and should run on one of the following operating systems: (1) Windows 10 64/86 bit, (2) Linux Ubuntu 14.04. Code written in Matlab is also acceptable at condition that it runs on Matlab 2021. In case of any special setting needed for the proper running of the algorithm, a README file is expected.
- Executables that do not match the requirements above could be discarded from the contest at the discretion of the Evaluating Committee.
- Executables must be sent by the email address chosen for the registration to biplab@unisa.it. Please, put the chosen username in the subject of the email. In case of multiple submissions, please report details of the algorithm in the body of the email,
Dataset
The M2FRED dataset developed by Biometric and Image Processing Lab (BIPLab) research laboratory at University of Salerno, is a multimodal frontal face database that includes digital videos of 50 subjects. Each subject was required to register using their mobile device following precise acquisition rules for several distinct sessions. The protocol provides that each individual is recorded in several distinct and timed sessions over a period of time not limited to a single day. The construction of the dataset is in fact faithful to the normal conditions of use of a recognition system in real conditions, which foresee a variability of the same subjects over time. The subjects were asked to face the camera, making sure that their face is entirely framed in the video stream of the mobile phone used for recording. Participants’ videos were acquired with short recordings (a few minutes), pronouncing suggested phrases or words according to the defined protocol.
The acquisitions were divided into 4 sessions, in physical and environmental conditions not necessarily the same.
The position of the camera relative to the face was the same.
Each subject has pronounced the following sentences:
- Zero, one, two, three, four, five, six, seven, eight, nine”.
- Good for evil is charity, evil for good is cruelty”.
- Hello, my name is “participant’s name”, my favorite color is \participant’s preferred color “.
- Tell an anecdote or a joke.
In each session, a single recording of all the phrases above mentioned was processed and suitably separated by a 3 second pause. Within the same acquisition, the subject first recovered without the mask and then with the facial mask. Each session took place on a separate day of the week, interspersed with 16 indoor and outdoor acquisitions.
The dataset structure is :
- 50 subjects with ID number from 000 to 049
- 2 folder for each subject: one withOUT mask (i.e., 000_0) one with mask (i.e., 000_1)
- 16 videos for each folder: 8 indoor/8 outdoor
To have an overall view of how the data are organized in the M2FRED dataset, here there is a visual representation:
M2FRED_dataset
├───000_0 #Identity of the first subject WITHOUT mask
│ 000_1_0_1.avi
│ 000_1_0_2.avi
│ …
│ 000_4_0_3.avi
│ 000_4_0_4.avi
├───000_1 #Identity of the first subject WITH mask
│ 000_1_1_1.avi
│ 000_1_1_2.avi
│ …
│ 000_4_1_3.avi
│ 000_4_1_4.avi
│
├───…
│
├───049_0
│ 049_1_0_1.avi
│ 049_1_0_2.avi
│ …
│ 049_4_0_3.avi
│ 049_4_0_4.avi
│
└───049_1 #Identity of the fiftieth subject WITH mask
049_1_1_1.avi
049_1_1_2.avi
…
049_4_1_3.avi
049_4_1_4.avi
The namespace of each video is the following:
001_1_0_1
ID_[1-4]_[0/1]_[1-4]
- [ID]: Subject ID
- [1-4]: Session number
- [0/1]: 0 acquisition without mask 1 acquisition with mask
- [1-4]: Acquisition number
The dataset is available at the following http://biplab.unisa.it/home/m2fred.
Important Dates
- Competition Opens: 15th November 2021
- Algorithm Submission Deadline:
1st February 202220th February 2022 - Verification Results: 26th February 2022
- Final rank: 2nd March 2022
Workshop and Special Issue submission
Best selected algorithms will be invited to be presented in the ICIAP 2021 workshop “Parts can count like the Whole”. The authors of the top three algorithms can submit a paper that will be peer-reviewed as all other contributions to the workshop and added in the proceedings of the conference in case of positive review.
We strongly encourage to join the competition since the best algorithms can have the further option of submitting a paper to a Special Issue on Elsevier Pattern Recognition Letters that will open by the end of this year (pending).
Organizers

Lucia CIMMINO

Fabio NARDUCCI
Technical Program Committee
- Michele Nappi – University of Salerno
- Maria de Marsico – University of Rome “La Sapienza”
- Amine Nait-Ali – University of Paris-Est Créteil
- Florin Pop – University of Bucharest
- Modesto Castrillón – University de Las Palmas de Gran Canaria
- Daniel Riccio – University of Naples Federico II
- Carmen Bisogni – University of Salerno
- Chiara Pero – University of Salerno
- Lucia Cascone – University of Salerno
- Paola Barra – University of Rome “La Sapienza”
- Silvio Barra – University of Naples Federico II
- David-Freire Obregón – University de Las Palmas de Gran Canaria
Contact us
If you want to contact us, feel free to send an email to biplab@unisa.it.